多节点分布式训练
分布式训练是实现大模型研发的关键技术,它通过并行化解决了数据、计算与时间的核心矛盾,在效率、规模和可靠性上为训练超大模型提供了基础支持。
前提条件
概览
下文以双节点运行任务为例,演示多节点分布式训练的配置。
操作步骤
-
登录账号后,单击悬浮工作台中的“新建实例/VSCode”菜单项,进入实例参数配置页面,如下图所示。将卡数设置为
8,启动该实例,并将其命名为“实例A”。随后,请参照下图再次启动一个新实例,命名为“实例B”。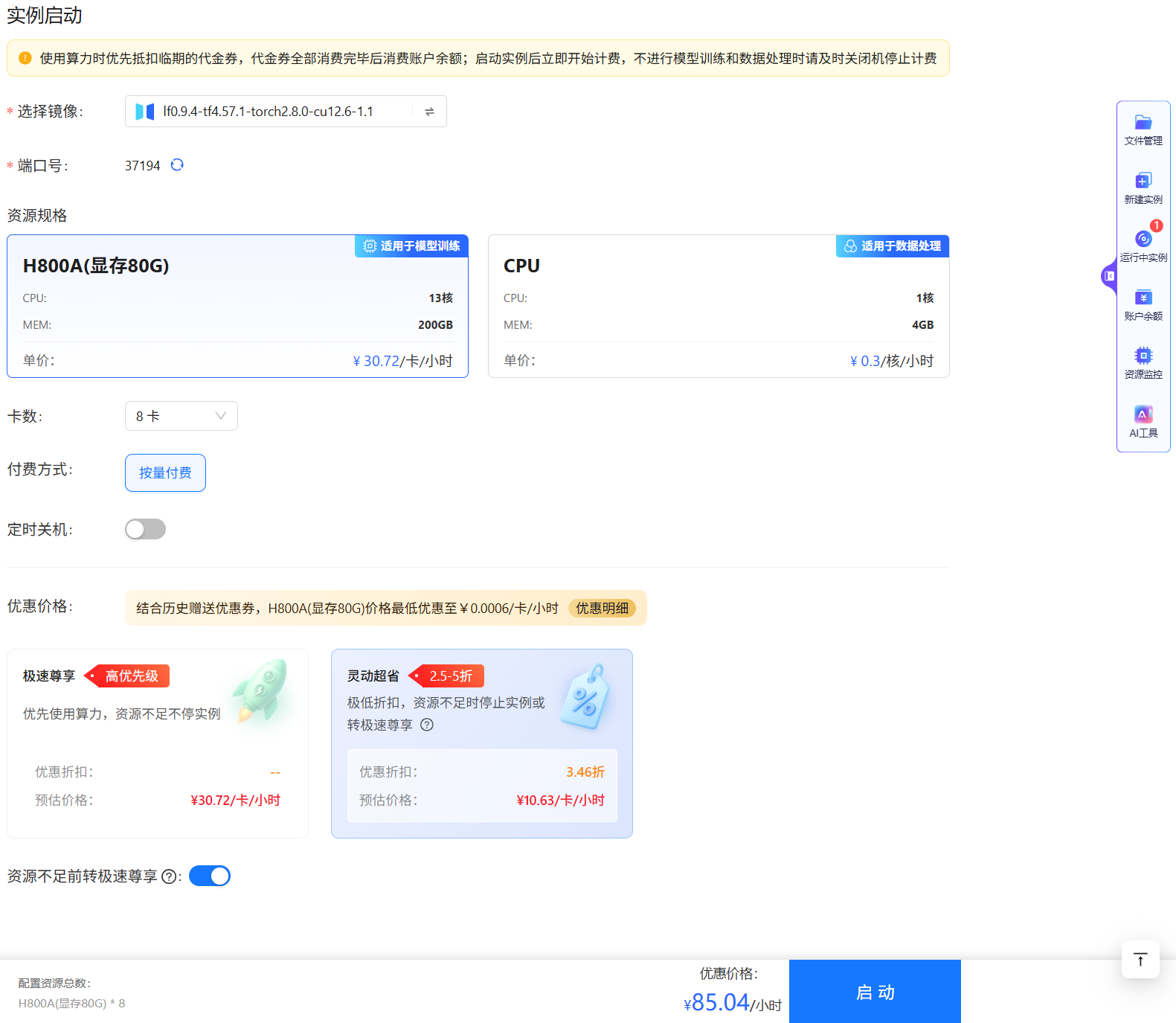
-
实例启动后,在终端运行如下所示的命令将环境切换至
lf环境,您也可以自定义环境。conda activate lf -
在本示例中我们设定“实例A”为master节点,运行如下所示的命令获取master节点的IP地址。
ifconfig -
下载脚本文件一、脚本文件二,解压上述文件后,将
mmmc-0.sh拖拽至“实例A”VS Code任一目录,如:/workspace/user-data/others,将mmmc-1.sh拖拽至“实例B“VS Code任一目录,如:/workspace/user-data/others。文件参数说明如下表所示。
参数 默认值 说明 GPUS_PER_NODE8每个实例(节点)使用的 GPU 数量。对于H100/B200标准机型通常为 8。 NCCL_IB_DISABLE0是否禁用 IB网络。设置为0以确保启用InfiniBand进行高速通信。NCCL_SOCKET_IFNAMEeth0指定用于Bootstrap(引导)和控制流的网卡名称。 NCCL_IB_HCAib7s指定用于数据传输的 IB 网卡前缀。 NNODES[节点总数]参与训练的总机器(节点)数量。例如 2 机 16 卡则填 2。 NODE_RANK[当前节点序号]当前机器的排名序号,从 0 开始计数(第一台为 0,第二台为 1)。 MASTER_ADDR172.19.xxx.xx主节点(Rank 0)的 IP 地址。 MASTER_PORT29500(或其他空闲端口)主节点监听的端口号,用于进程间同步,确保所有节点该端口一致。 -
将
mmmc-0.sh和mmmc-1.sh脚本文件中的MASTER_ADDR修改为实际master节点的IP地址。 -
请将
mmmc-0.sh和mmmc-1.sh脚本文件中的swanlab_api_key替换为您实际注册账号的API Key。您可在登录SwanLab后,进入[个人中心/设置/常规/开发]页面获取该密钥,如下图所示。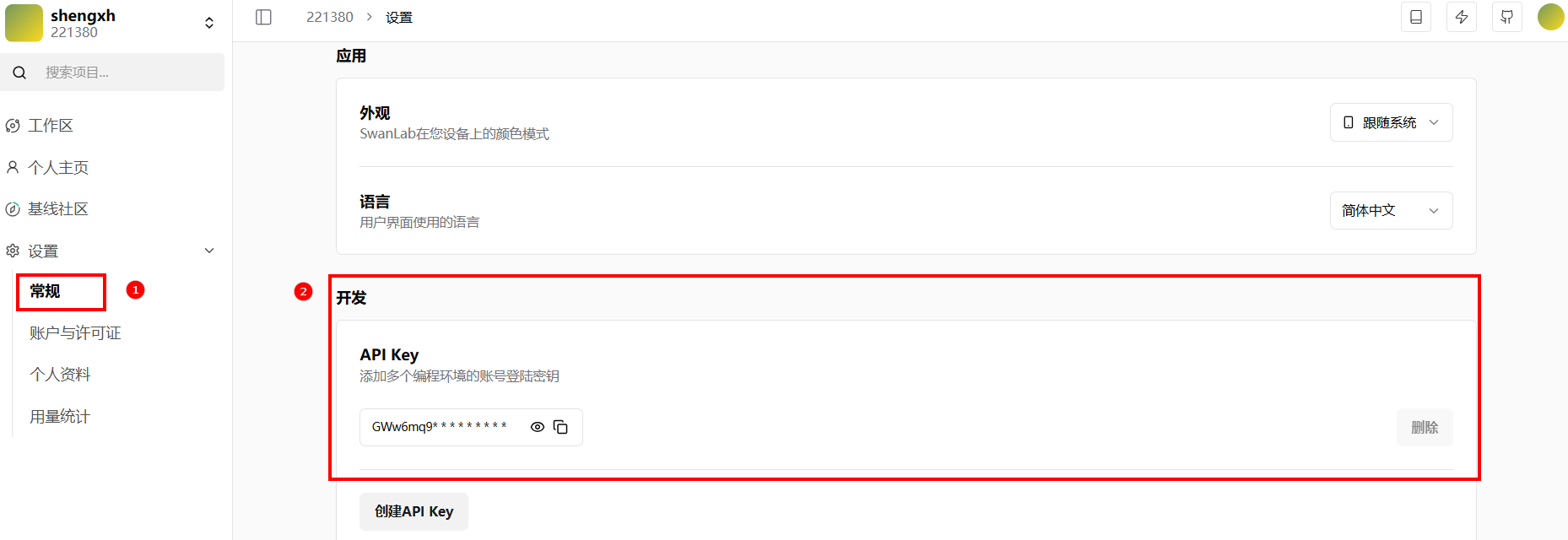
-
其余参数可以保持默认值,保存上述修改。脚本文件配置完成后,发现两个实例之间已经实现通信,例如下图所示。
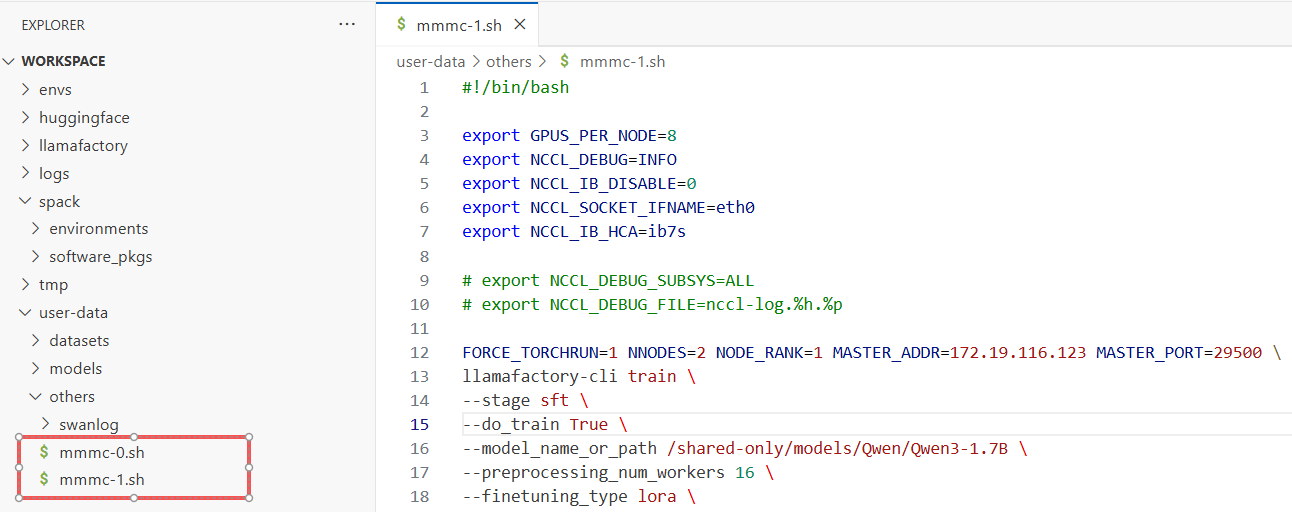
-
-
在master节点的终端运行如下所示的命令,然后在终端观察训练过程,例如下图所示。
sed -i 's/\r$//' mmnc-0.sh
chmod +x mmnc-0.sh
./mmnc-0.sh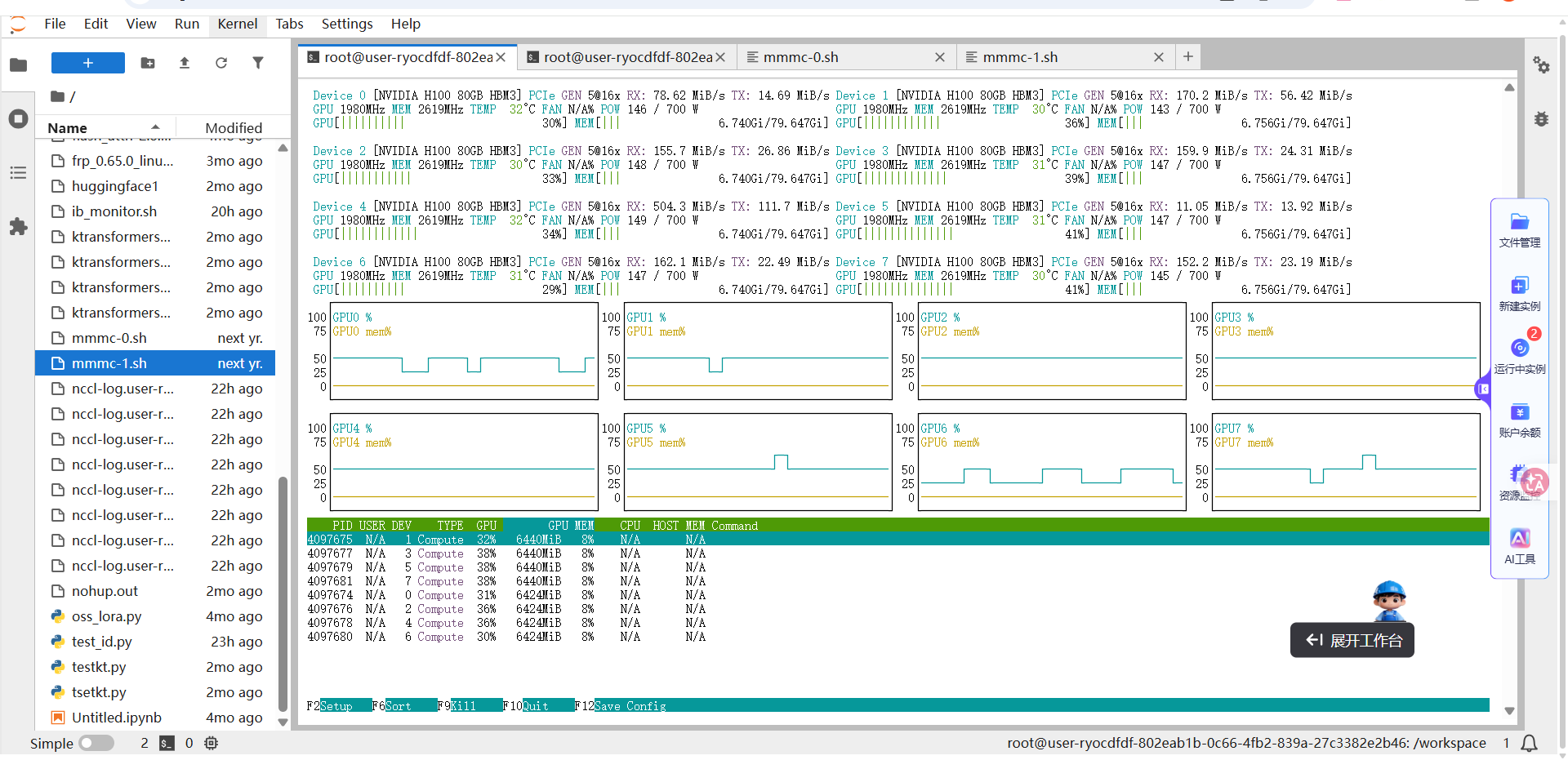
-
同时,在实例B的终端运行如下所示的命令,启动服务,然后在终端观察训练过程,例如下图所示。
sed -i 's/\r$//' mmnc-1.sh
chmod +x mmnc-1.sh
./mmnc-1.sh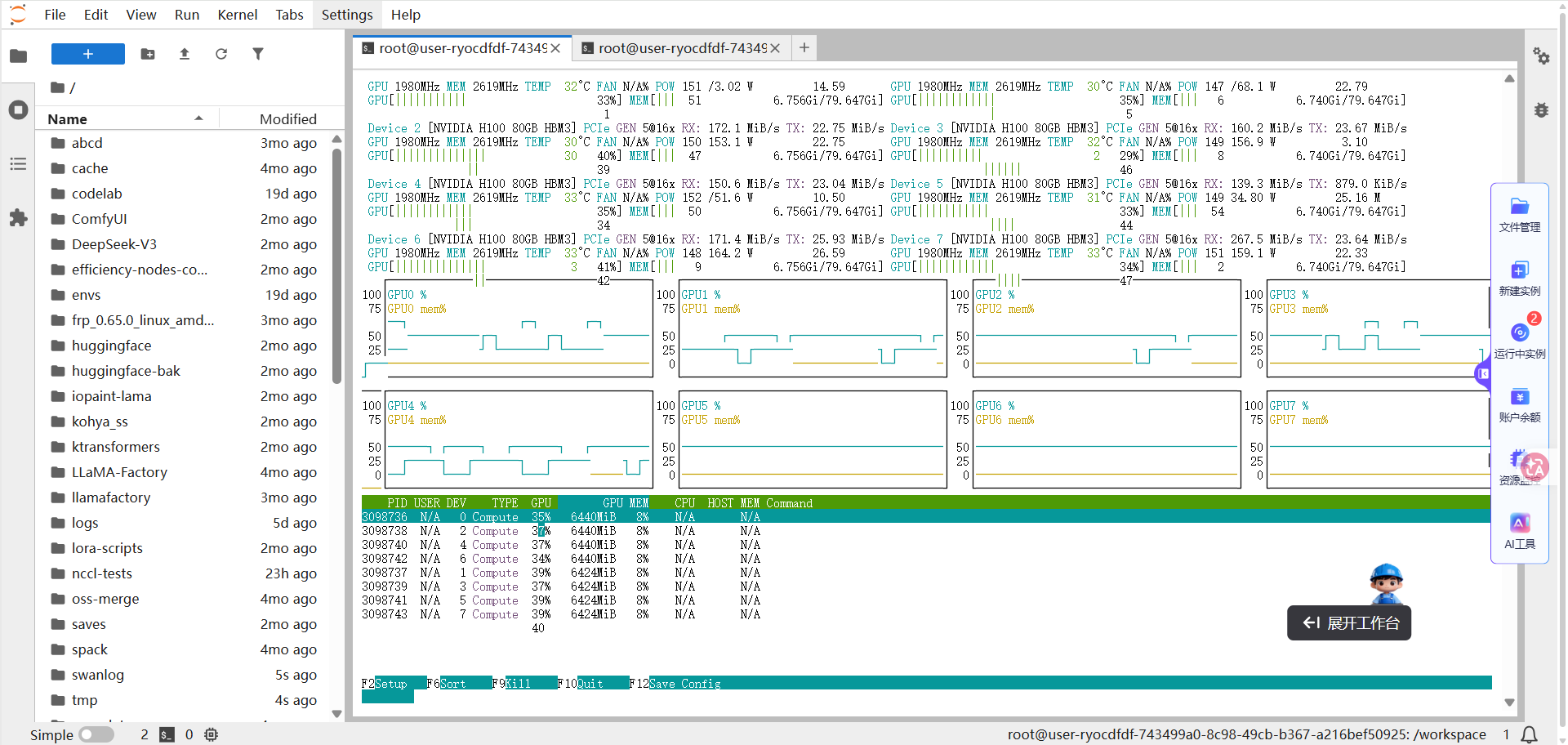 提示
提示您可运行
apt update && apt install nvtop命令安装NVIDIA GPU实时监控工具。 -
训练过程中,通过SwanLab监控实验指标可见:
train/loss曲线平滑,数值从5.3稳步下降至2.0;与此同时,grad_norm也同步回落,表明模型在整个训练过程中表现稳定,收敛良好。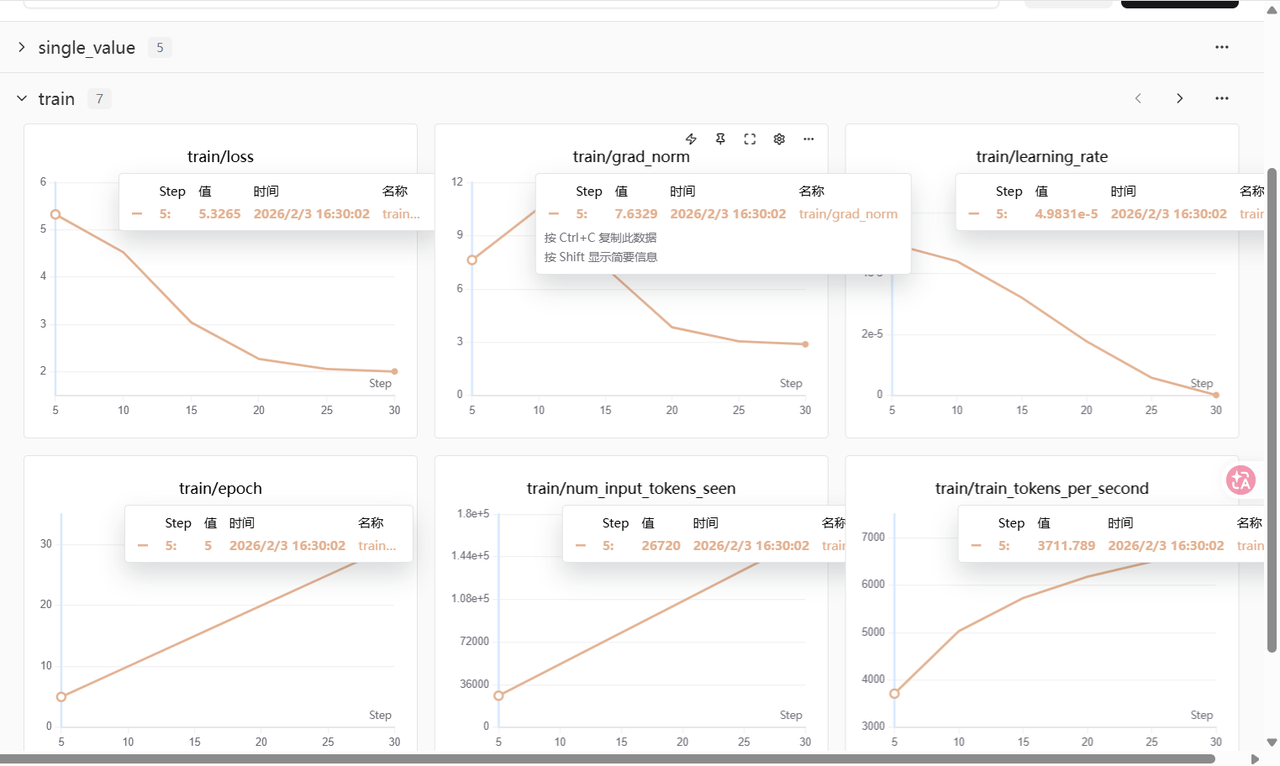
总结
从上述示例可以看出,分布式训练通过在多个计算节点之间协同工作,有效利用集群资源,显著提升模型训练的效率。具体而言,用户可通过配置关键通信参数(如MASTER_ADDR指定主节点地址、NODE_RANK标识当前节点在集群中的序号),建立节点间的高效通信机制。在此基础上,训练任务被拆分并分配至多个GPU并行执行,不仅大幅缩短了整体训练时间,还能够支持更大规模的模型和数据集。这种横向扩展使得分布式训练成为现代深度学习系统中不可或缺的核心技术之一。