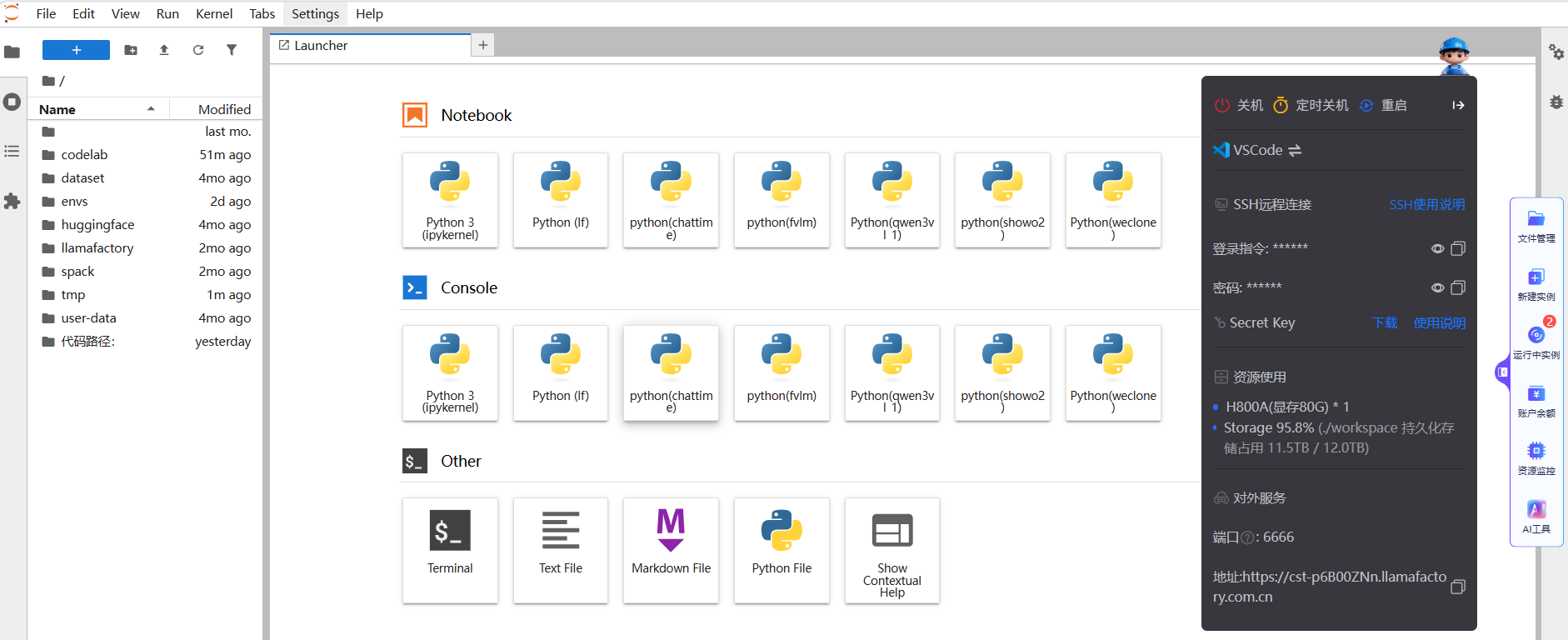
实例管理
大模型实验室不仅是科研基地,更是强大的高性能算力平台。 平台以H800A(80G 显存)为核心算力单元,支持一键启动JupyterLab、VSCode及LlamaFactory Online实例。无论是模型训练、微调,还是数据集下载与处理,您均可通过新建实例灵活定制,轻松驾驭从数据准备到模型落地的全流程任务。 H800A (80G) 加速卡的核心硬件规格与性能指标如下表所示。
| 型号 | 显存 | CPU | 内存 | 显存带宽 | 单卡FP16算力 | NVLink | 计算网络 | 存储网络 |
|---|---|---|---|---|---|---|---|---|
| H800A (80G) | 80 GB | 13 cores | 200 GB | 3.35 TB/s | 989 TFLOPS | 1.6 TB/s | 400 GB/s | 50 GB/s |
前提条件
用户已注册大模型实验室,如果需要帮助或尚未注册,可参考账户注册/登录完成注册/登录。
概览
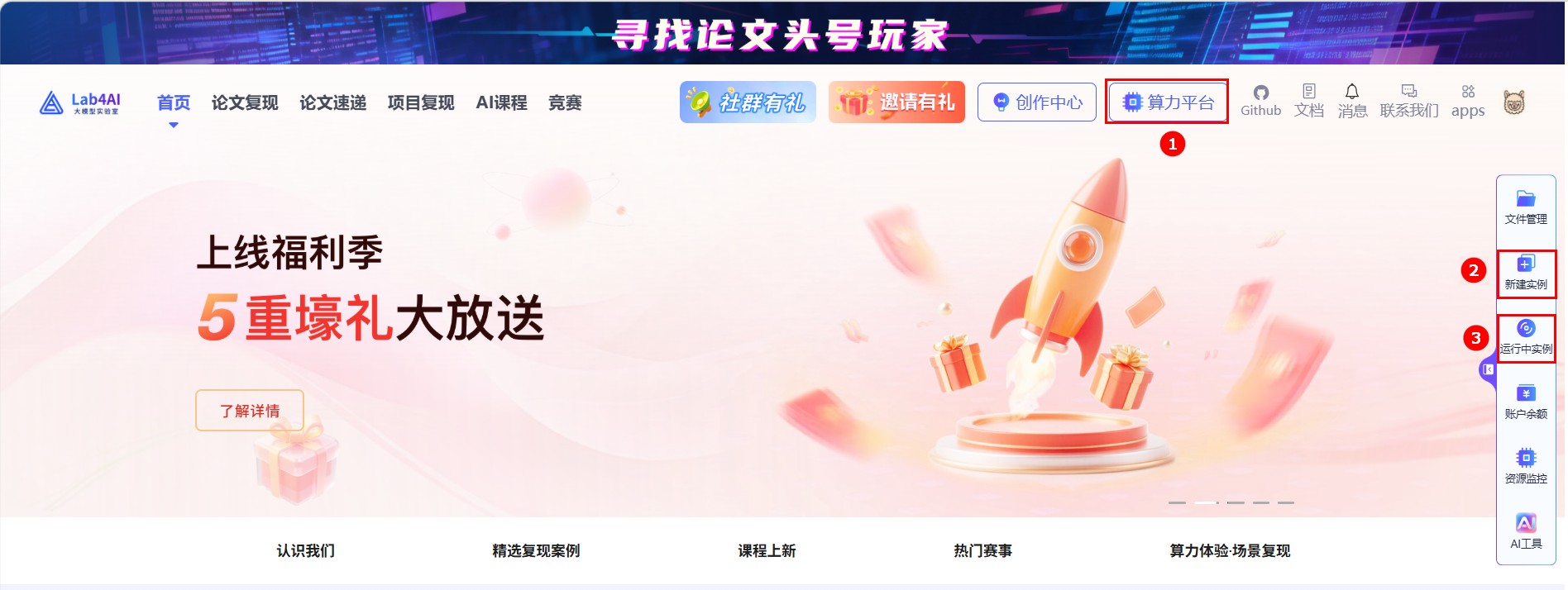
可在此快速创建并启动高性能的GPU与CPU实例,灵活满足各类计算需求。新建实例广泛适用于模型下载、数据集获取、数据预处理及各类自定义开发与训练任务。依托强大的云端算力资源,您能够高效完成从开发调试到大规模训练的数据管理全流程操作。通过简洁直观的管理界面,实现资源的便捷管控,助力您的AI研发与数据处理工作更加快速、灵活、可靠地推进,示例页面如下所示。
| 序号 | 模块名称 | 模块说明 |
|---|---|---|
| ① | 新建实例 | 您可以通过首页“算力平台”入口(如上图①所示),或点击悬浮菜单栏中的“新建实例”按钮(如图②所示),快速创建JupyterLab、VSCode及LlamaFactory Online实例。 |
| ② | 运行中实例 | 查看当前运行的实例(含论文复现、项目复现等),并提供一键关闭实例、重置资源以及SSH远程连接等便捷功能。 |
LlamaFactory Online实例指的是支持用户通过LlamaFactory Online WebUI启动实例,启动WebUI后您可以进行自定义模型训练、评估、对话、导出等操作。
操作步骤
平台为用户提供了完整的AI开发环境,支持从数据准备、模型训练到服务部署的全流程操作,详情可参考下文。
启动实例
- Jupyter Lab
- VSCode
- LlamaFactory实例
- 悬浮操作框
-
登录大模型实验室后,您可以通过以下任一方式进入启动实例:
- 点击首页的“算力平台”入口,如上图高亮①所示。
- 点击悬浮菜单栏中的“新建实例”按钮,如上图高亮②所示。
-
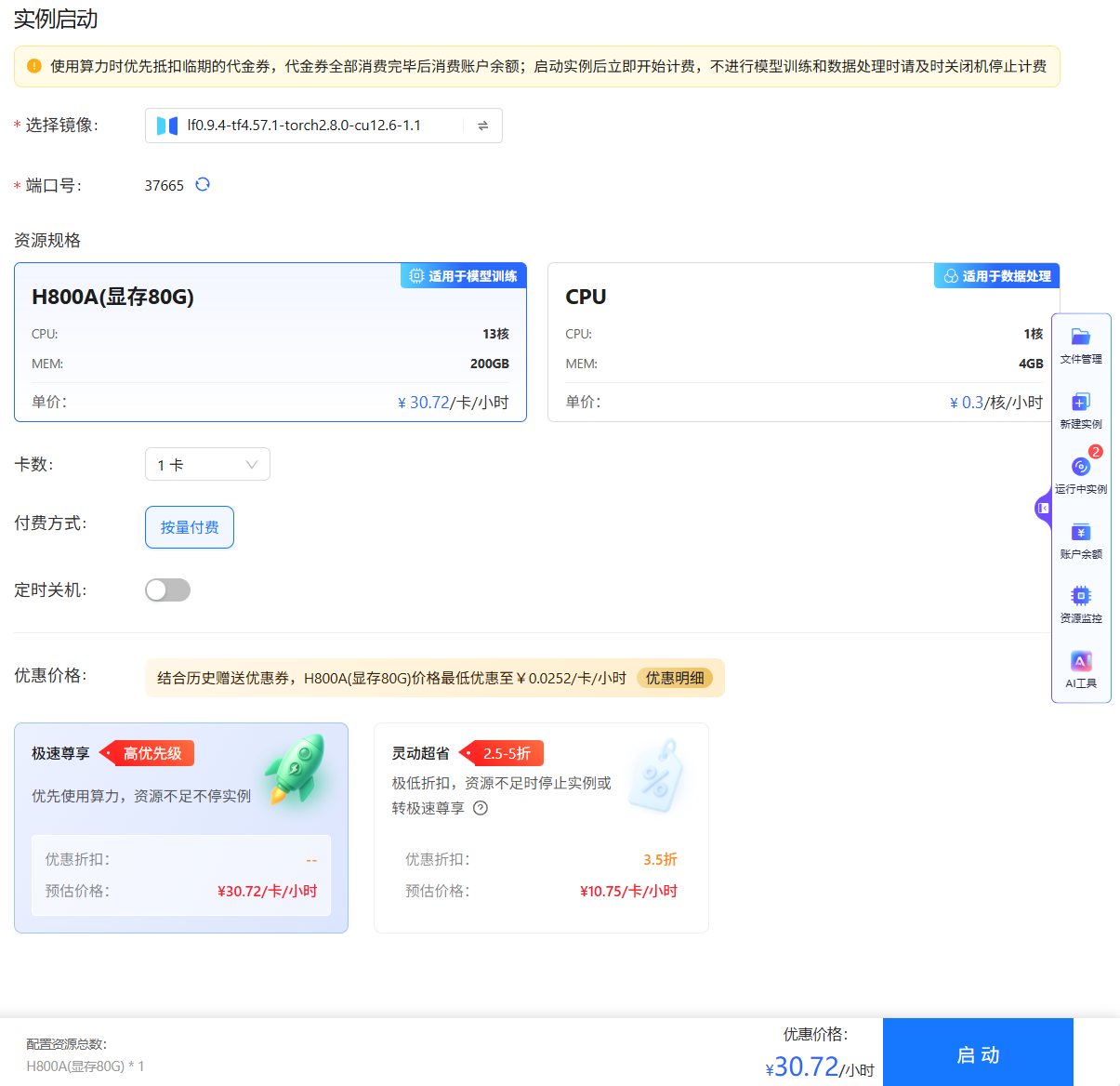
选择“JupyterLab”图标,进入实例启动参数配置页面,例如下图所示。
-
根据模型等参数选择对应版本的镜像,单击
 图标,进入镜像选择页面,例如下图所示,单击“查看模型镜像列表”查看对应的镜像列表,例如下图高亮①所示,镜像选择完成后,单击“确定”按钮即可。
图标,进入镜像选择页面,例如下图所示,单击“查看模型镜像列表”查看对应的镜像列表,例如下图高亮①所示,镜像选择完成后,单击“确定”按钮即可。
您也可以点击“筛选”链接,例如下图高亮②所示,根据
cuda、transformers、pytorch、LLaMAFactory版本筛选所需的镜像,各类组件的可能组合可参看查看模型镜像列表。 -
用户注册后首次启动实例时,系统会自动推荐一个远程访问端口(例如:36458)供其使用,该端口可用于SSH等服务的连接。如果用户不想使用系统推荐的端口号,可以点击端口号的 “刷新” 按钮,系统将随机生成一个新的端口号。
提示-
当用户关闭当前实例后,如果短期内再次启动实例,并且这个端口号没有被其他用户占用,那么系统保留原来的端口号。
-
如果用户关闭实例后,间隔了很长时间没有启动实例,该端口号很可能被系统释放并分配给其他用户。此时,当用户再次启动时,那么系统就必须为他分配一个新的、未被占用的端口号。
-
- GPU
- CPU
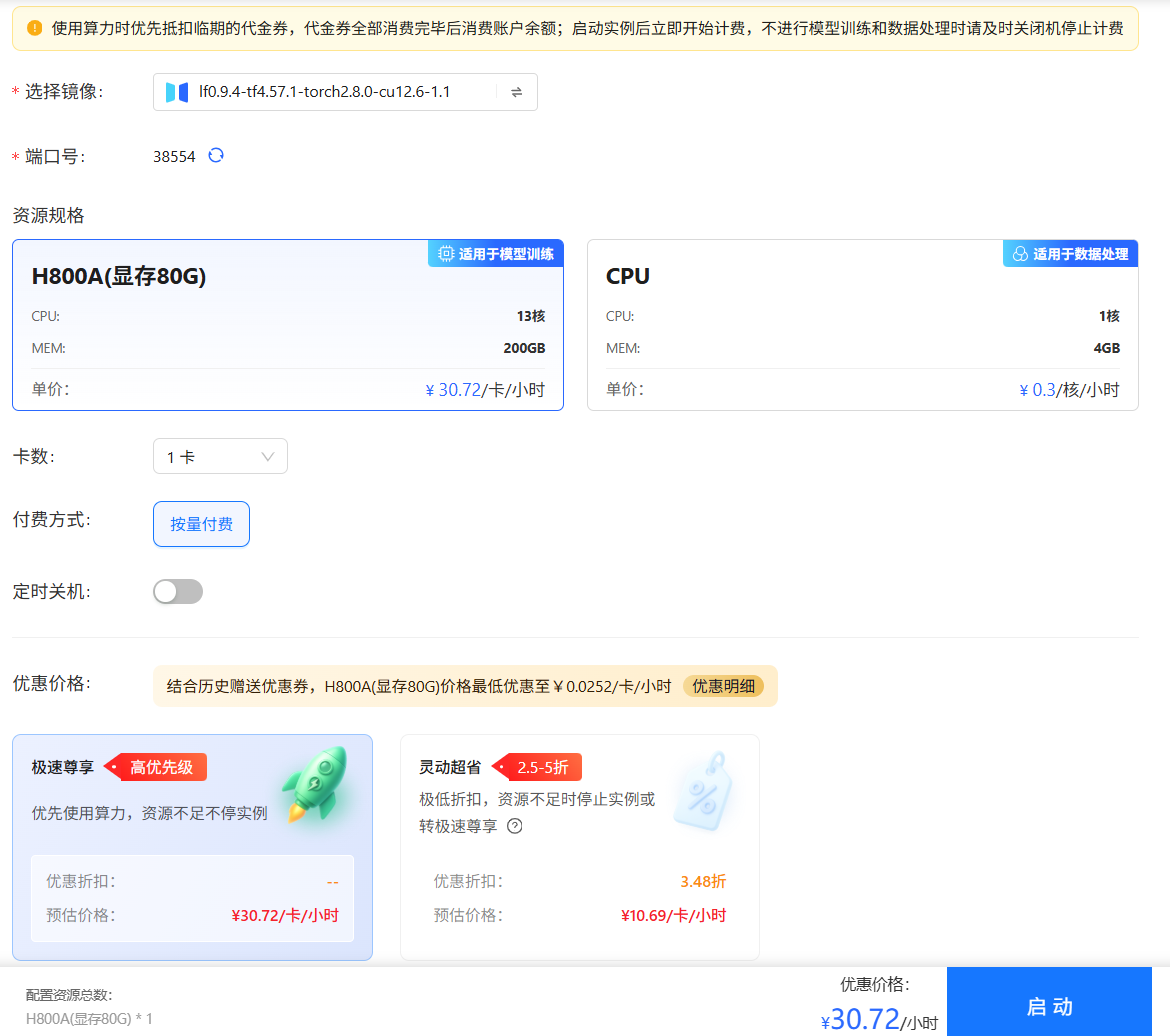
- 如果用户选择GPU资源规格,待配置参数说明如下所示。
-
资源规格:选择"H800A(显存80G)",该类型的资源适用于大模型训练、微调、推理等并行计算场景。
-
卡数:选择待使用的GPU卡数,平台支持选择
1卡、2卡、3卡、4卡、5卡、6卡、7卡、8卡等卡数。 -
付费方式:选择GPU卡的扣费方式,目前平台支持
按量付费,即按照GPU的实际使用时长进行付费。 -
为当前实例配置定时关机策略,即设置自动关机时间。
-
优惠价格:平台提供H800A(80G显存)显卡算力服务的两种不同套餐,核心区别在于服务优先级和价格,以满足不同场景和预算的需求,详情如下所示。
- 极速尊享:提供高优先级保障、资源紧张时也不会中断实例的稳定服务。
- 灵动超省:享受极高折扣、但资源紧张时可能被停止实例的低成本、可中断型服务,支持选择“实例停止前转极速尊享”。
开启此模式后,当常规资源不足时,您的实例将自动升级至“极速尊享”模式继续运行,不会因资源问题而停止。此期间将按“极速尊享”的标准价格计费。
- 如果用户选择CPU资源规格,待配置参数说明如下所示。
-
资源规格:选择"CPU",该类型的资源适用于数据处理等场景。
-
卡数:选择待使用的CPU卡数,平台支持选择
2核、4核、8核、16核等核数。 -
付费方式:选择CPU卡的扣费方式,目前平台支持
按量付费,即按照CPU的实际使用时长进行付费。 -
为当前实例配置定时关机策略,即设置自动关机时间。
-
启动后页面如下图所示,各目录的说明见下表。
目录名称 说明 codelab 用于存储论文和项目复现所用的代码、数据集、模型等文件。 envs 当前conda环境中,用户自定义安装依赖包的目录。 huggingface Hugging Face 工具自动创建的本地缓存目录,可以用来存放下载的预训练模型文件、数据集缓存。 llamafactory llama factory操作的相关目录:包含数据集,data目录、服务启动日志、logs日志、output训练保存目录、config配置目录。 spack 用于存储用户自定义的软件环境,隔离软件依赖。 tmp tmp临时文件,用于存储临时缓存等。 user-data 此目录是用户在通过任务模式下上传或者产生的数据;通过SFTP上传/下载数据;执行训练过程中产生的数据或者配置存储在models下的output目录中。
-
登录大模型实验室后,您可以通过以下任一方式进入启动实例:
- 点击首页的“算力平台”入口,如上图高亮①所示。
- 点击悬浮菜单栏中的“新建实例”按钮,如上图高亮②所示。
-
选择“VSCode”图标,进入实例启动参数配置页面,例如下图所示。
-
根据模型等参数选择对应版本的镜像,单击
图标,进入镜像选择页面,例如下图所示,单击“查看模型镜像列表”查看对应的镜像列表,例如下图高亮所示,镜像选择完成后,单击“确定”按钮即可。
- GPU
- CPU
- 如果用户选择GPU资源规格,待配置参数说明如下所示。
- 资源规格:选择"H800A(显存80G)",该类型的资源适用于大模型训练、微调、推理等并行计算场景。
- 卡数:选择待使用的GPU卡数,平台支持选择
1卡、2卡、3卡、4卡、5卡、6卡、7卡、8卡等卡数。 - 付费方式:选择GPU卡的扣费方式,目前平台支持
按量付费,即按照GPU的实际使用时长进行付费。 - 为当前实例配置定时关机策略,即设置自动关机时间。
- 优惠价格:平台提供H800A(80G显存)显卡算力服务的两种不同套餐,核心区别在于服务优先级和价格,以满足不同场景和预算的需求,详情如下所示。
- 极速尊享:提供高优先级保障、资源紧张时也不会中断实例的稳定服务。
- 灵动超省:享受极高折扣、但资源紧张时可能被停止实例的低成本、可中断型服务,支持选择“实例停止前转极速尊享”。
开启此模式后,当常规资源不足时,您的实例将自动升级至“极速尊享”模式继续运行,不会因资源问题而停止。此期间将按“极速尊享”的标准价格计费。
- 如果用户选择CPU资源规格,待配置参数说明如下所示。
- 资源规格:选择"CPU",该类型的资源适用于数据处理等场景。
- 卡数:选择待使用的CPU卡数,平台支持选择
2核、4核、8核、16核等核数。 - 付费方式:选择CPU卡的扣费方式,目前平台支持
按量付费,即按照CPU的实际使用时长进行付费。 - 为当前实例配置定时关机策略,即设置自动关机时间。
-
workspace目录如下图所示。各目录的说明见下表。

目录名称 说明 codelab 用于存储论文和项目复现所用的代码、数据集、模型等文件。 envs 当前conda环境中,用户自定义安装依赖包的目录。 huggingface Hugging Face 工具自动创建的本地缓存目录,可以用来存放下载的预训练模型文件、数据集缓存。 llamafactory llama factory操作的相关目录:包含数据集,data目录、服务启动日志、logs日志、output训练保存目录、config配置目录。 spack 用于存储用户自定义的软件环境,隔离软件依赖。 tmp tmp临时文件,用于存储临时缓存等。 user-data 此目录是用户在通过任务模式下上传或者产生的数据;通过SFTP上传/下载数据;执行训练过程中产生的数据或者配置存储在models下的output目录中。
-
登录账号后点击界面右侧悬浮菜单栏的“新建实例”图标,选择“LLaMA-Factory”图标,进入实例启动参数配置页面,例如下图所示。
-
根据模型等参数选择对应版本的镜像,单击
图标,进入镜像选择页面,例如下图所示,单击“查看模型镜像列表”查看对应的镜像列表,例如下图高亮①所示,镜像选择完成后,单击“确定”按钮即可。
您也可以点击“筛选”链接,例如下图高亮②所示,根据cuda、transformers、pytorch、LLaMAFactory版本筛选所需的镜像,各类组件的可能组合可参看查看模型镜像列表。
- 用户注册后首次启动实例时,系统会自动推荐一个远程访问端口(例如:37665)供其使用,该端口可用于SSH等服务的连接。如果用户不想使用系统推荐的端口号,可以点击端口号的 “刷新” 按钮,系统将随机生成一个新的端口号。
提示
-
当用户关闭当前实例后,如果短期内再次启动实例,并且这个端口号没有被其他用户占用,那么系统保留原来的端口号。
-
如果用户关闭实例后,间隔了很长时间没有启动实例,该端口号很可能被系统释放并分配给其他用户。此时,当用户再次启动时,那么系统就必须为他分配一个新的、未被占用的端口号。
-
- GPU
- CPU
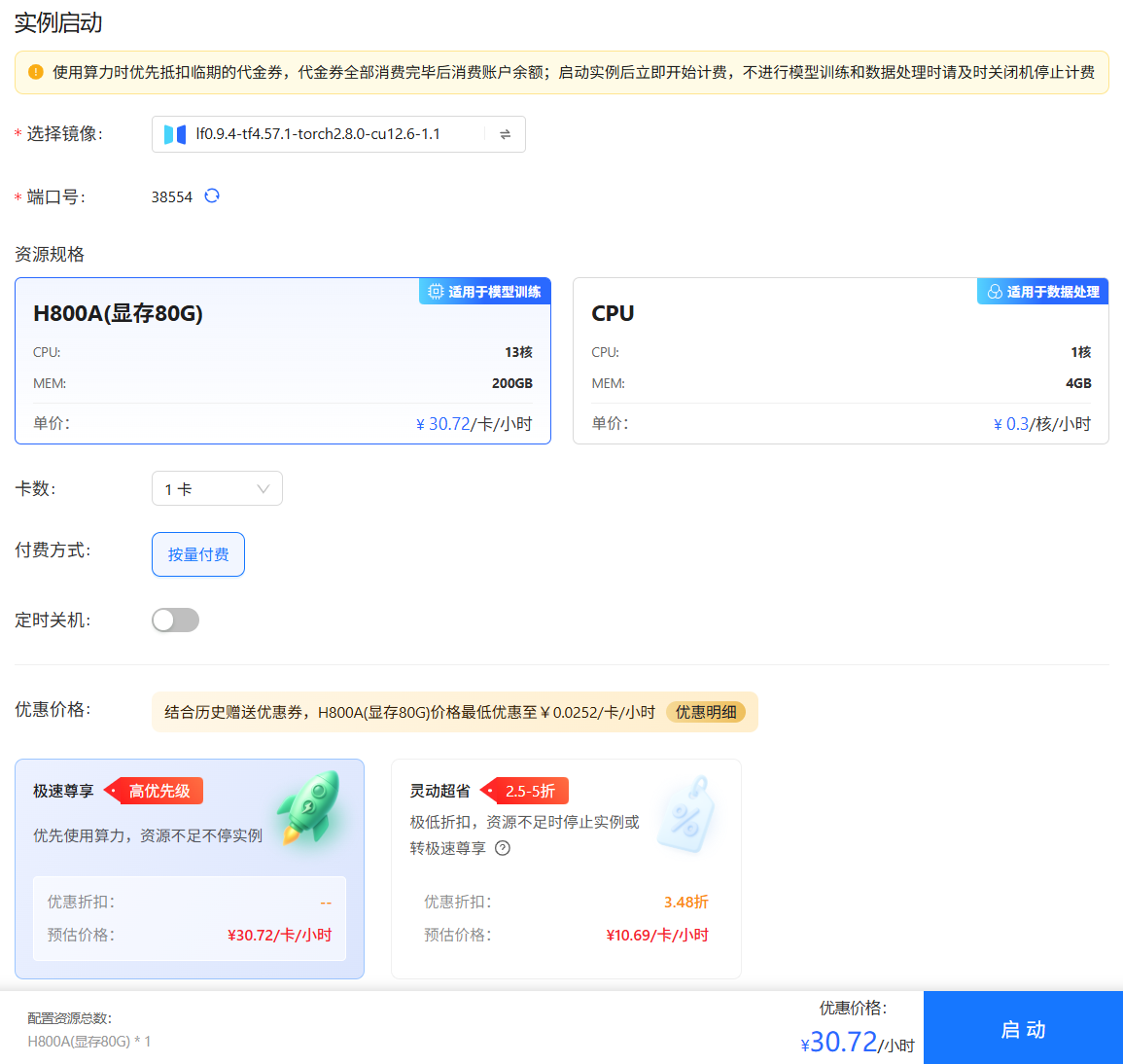
- 如果用户选择GPU资源规格,待配置参数说明如下所示。
-
资源规格:选择"H800A(显存80G)",该类型的资源适用于大模型训练、微调、推理等并行计算场景。
-
卡数:选择待使用的GPU卡数,平台支持选择
1卡、2卡、3卡、4卡、5卡、6卡、7卡、8卡等卡数。 -
付费方式:选择GPU卡的扣费方式,目前平台支持
按量付费,即按照GPU的实际使用时长进行付费。 -
为当前实例配置定时关机策略,即设置自动关机时间。
-
优惠价格:平台提供H800A(80G显存)显卡算力服务的两种不同套餐,核心区别在于服务优先级和价格,以满足不同场景和预算的需求,详情如下所示。
- 极速尊享:提供高优先级保障、资源紧张时也不会中断实例的稳定服务。
- 灵动超省:享受极高折扣、但资源紧张时可能被停止实例的低成本、可中断型服务,支持选择“实例停止前转极速尊享”。
开启此模式后,当常规资源不足时,您的实例将自动升级至“极速尊享”模式继续运行,不会因资源问题而停止。此期间将按“极速尊享”的标准价格计费。
- 如果用户选择CPU资源规格,待配置参数说明如下所示。
- 资源规格:选择"CPU",该类型的资源适用于数据处理等场景。
- 卡数:选择待使用的CPU卡数,平台支持选择
2核、4核、8核、16核等核数。 - 付费方式:选择CPU卡的扣费方式,目前平台支持
按量付费,即按照CPU的实际使用时长进行付费。 - 为当前实例配置定时关机策略,即设置自动关机时间。
- 进入LlamaFactory Online WebUI页面,例如下图所示。
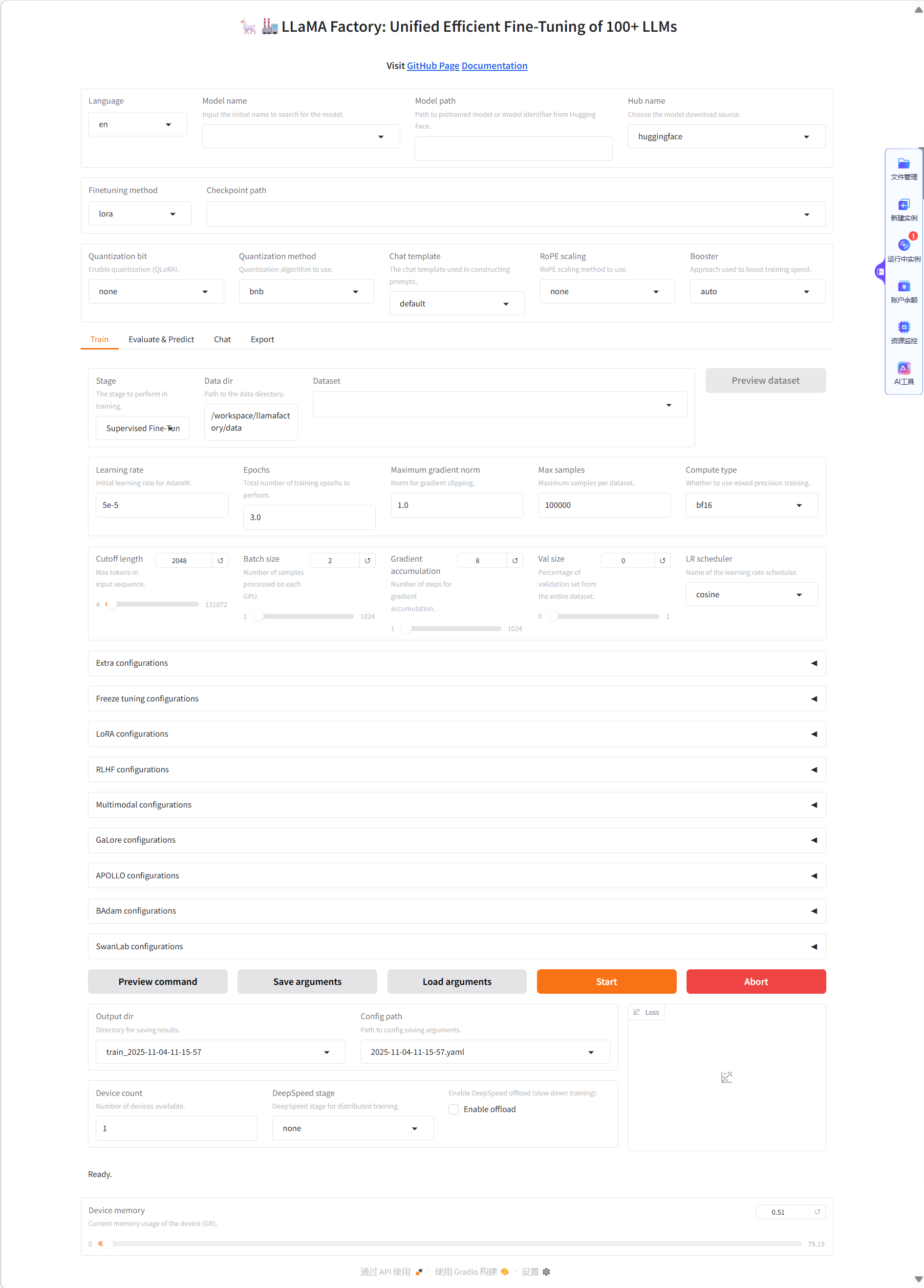
在模型微调页面,可根据需求进行模型微调,展开“训练”-“评估预测”-“推理聊天”-“导出模型”。
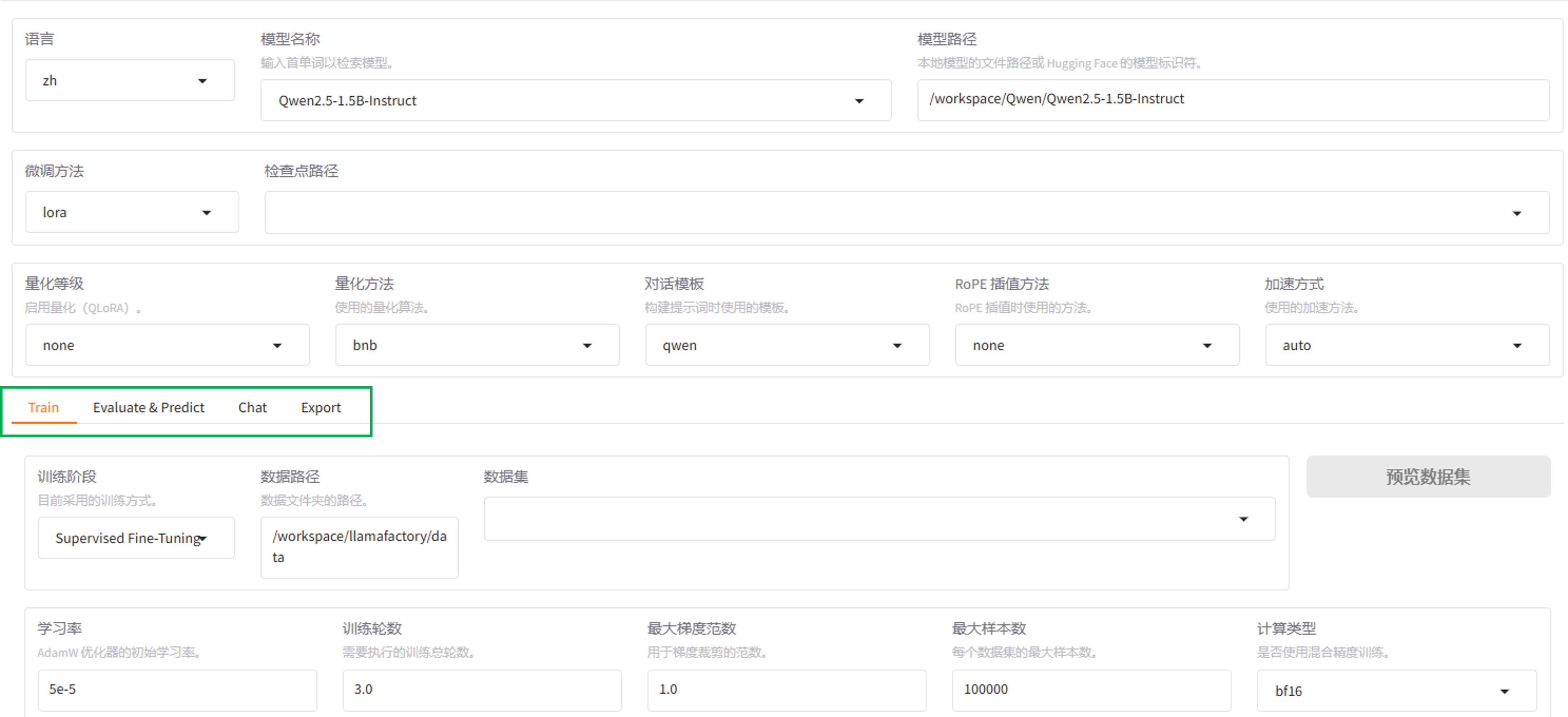
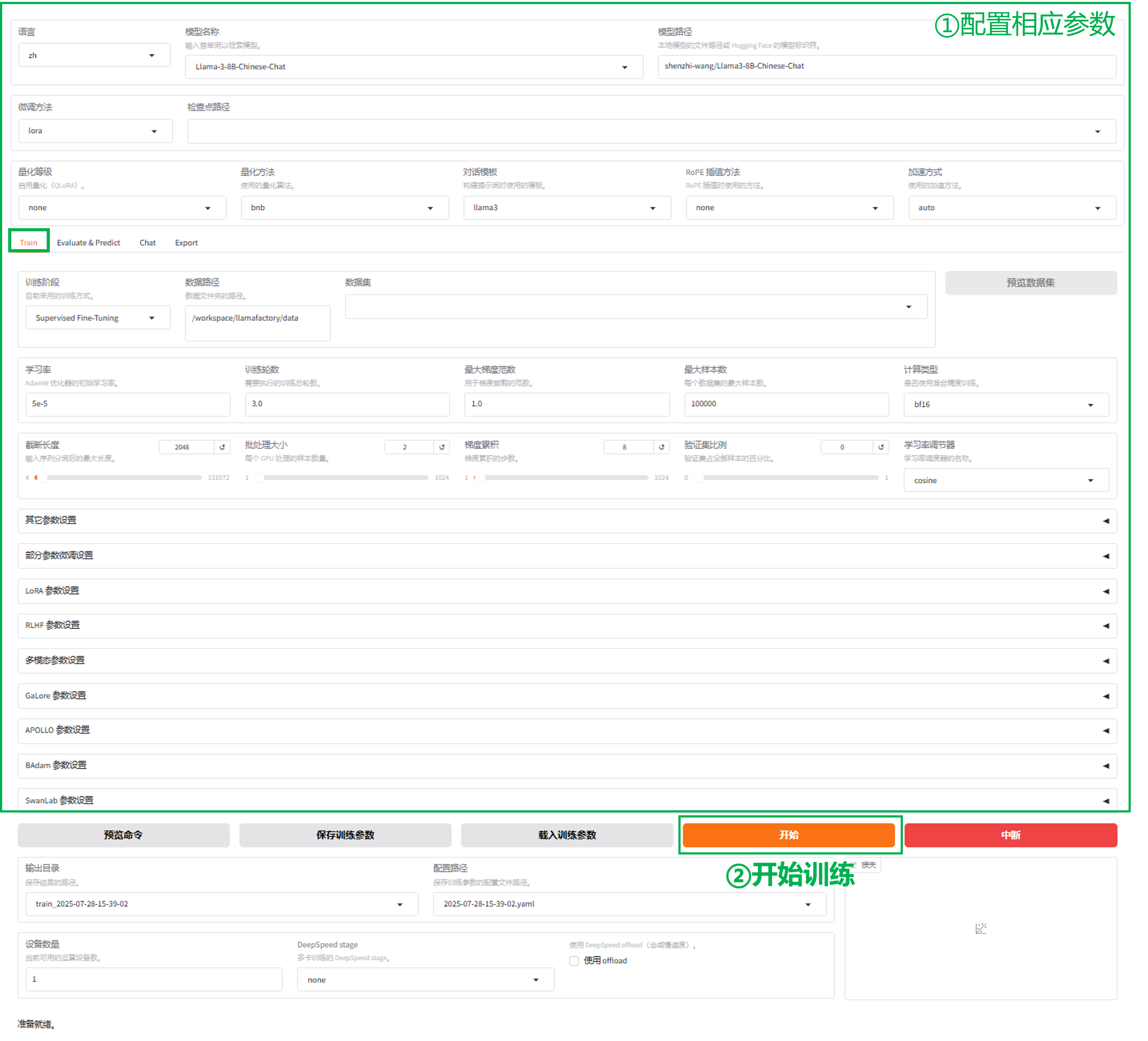
训练
1.选择模型
-
选择预置模型。预置模型存放在路径
/share-only/models下,您可以直接在“模型名称”处选择需要的模型,“模型路径”处会自动同步更新。
-
选择自定义的模型。模型路径
/share-only/models下没有的模型,需要用户自行下载。
回到实例空间,点击右侧“JupyterLab处理专属数据”进入工作空间下载。下载步骤:(以下载模型Qwen2.5-1.5B-Instruct为例)- 在JupyterLab工作空间中,点击启动面板(Launcher)下方的"Terminal"进入终端。

- 输入下载命令,完成下载。
huggingface-cli download --resume-download Qwen/Qwen2.5-1.5B-Instruct --local-dir Qwen/Qwen2.5-1.5B-Instruct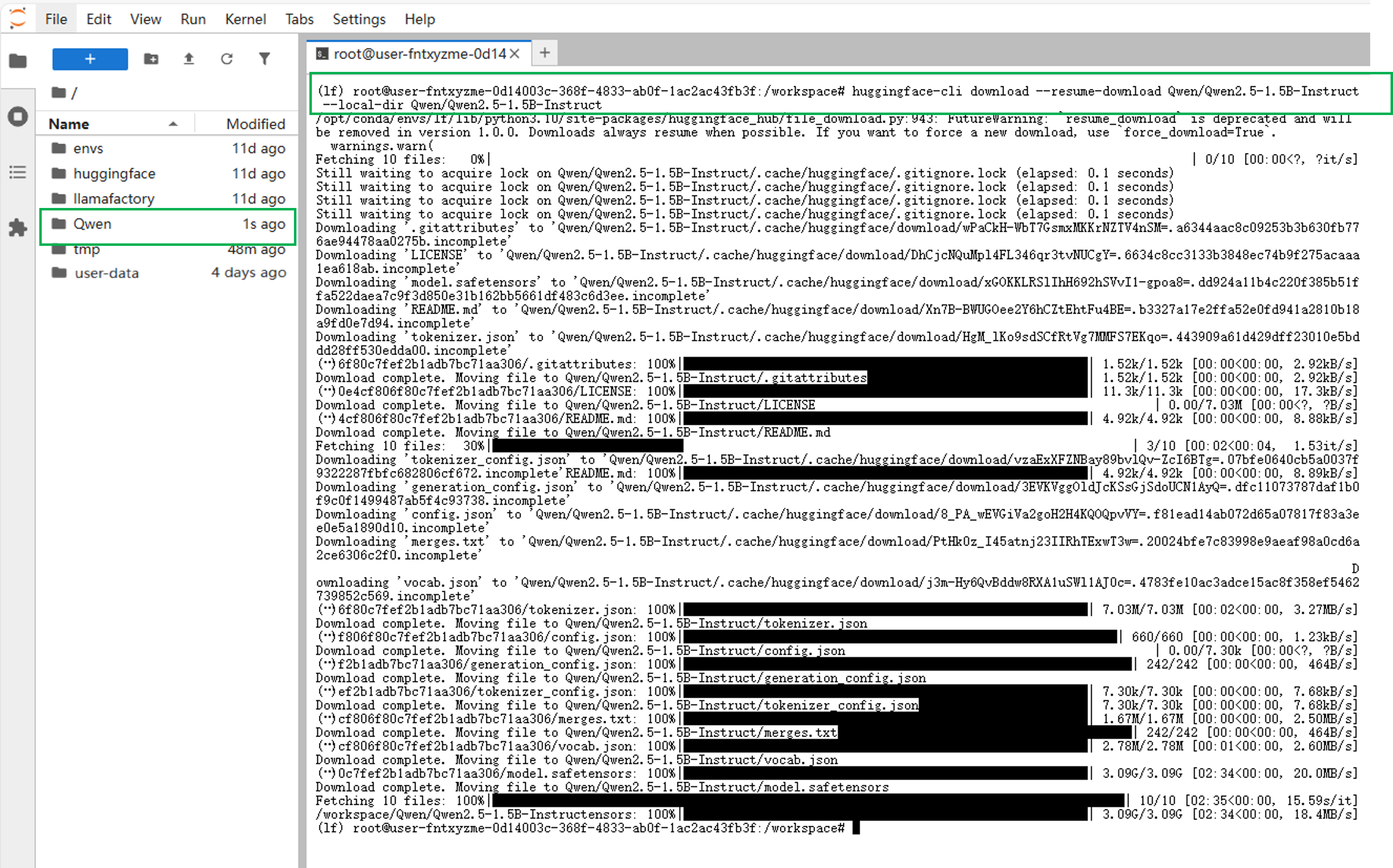 提示
提示上述指令中的
--local-dir Qwen/Qwen2.5-1.5B-Instruct语句,规定将模型下载到/workspace目录下。若不设置该命令,模型默认下载到/workspace/huggingface/hub目录下。- 回到"LLaMA-Factory快速微调模型" Web UI页面,在“模型名称”中找到Qwen2.5-1.5B-Instruct,模型路径要从
/workspace开始写起,写入上一步骤中模型存储的路径。

2.选择数据集
-
使用已预置的数据集。预置数据集存放在路径
/workspace/llamafactory/data下,您可以直接在“数据集”处选择需要的数据集。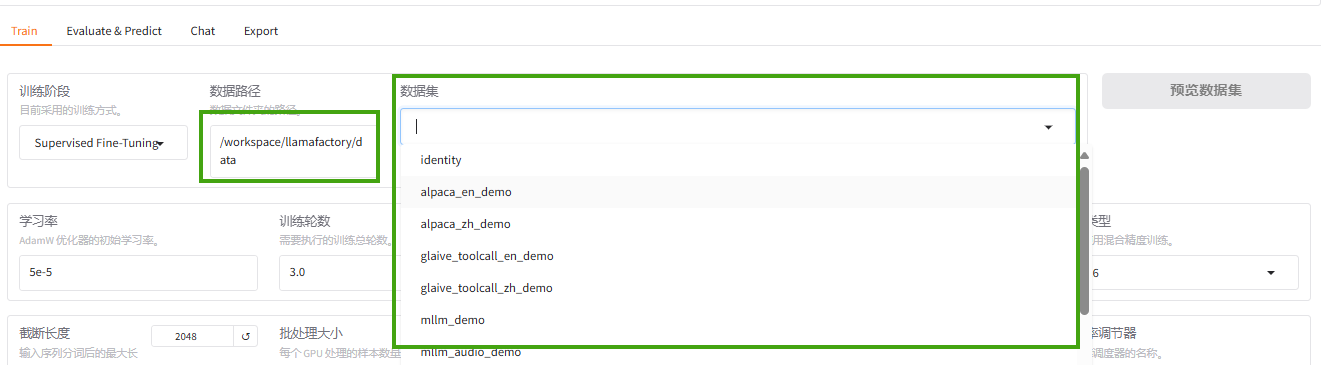
-
使用自定义的数据集。若您需要使用自定义的数据集,可参考数据上传中的JupyterLab上传。
3.开始训练
在训练界面,根据需求设置其他参数(参数设置可参考参数配置),点击“开始”进行训练。
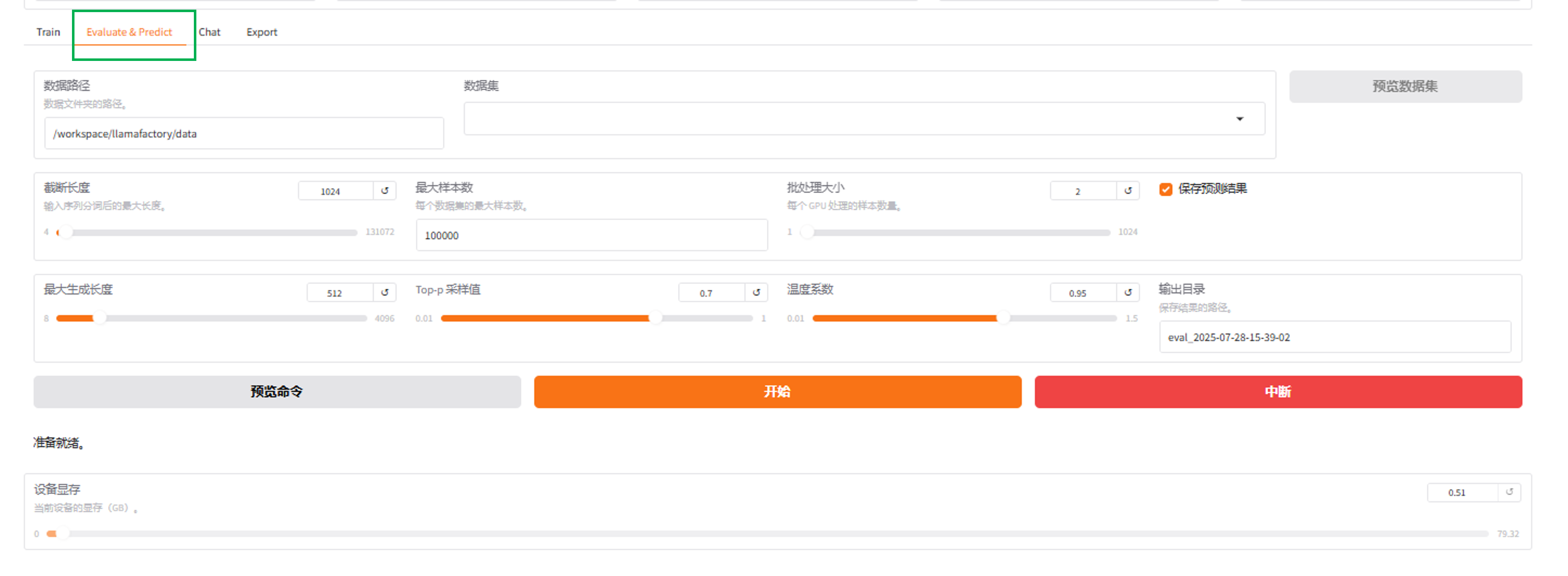
评估和预测
可以通过在评估与预测界面通过指定模型及适配器的路径在指定数据集上进行评估。
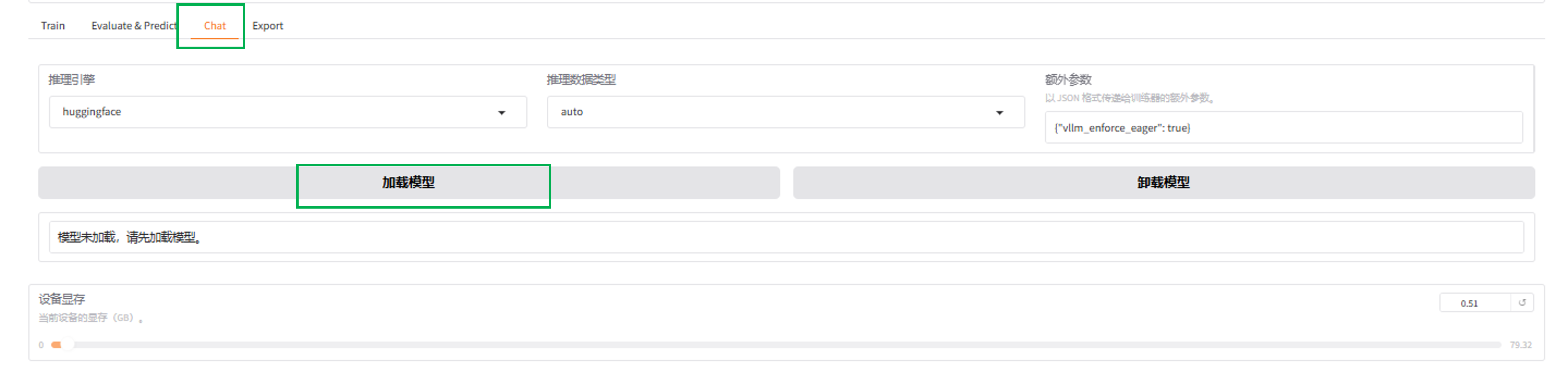
对话
在对话界面,通过指定模型、适配器及推理引擎,输入对话内容与模型进行对话观察效果。
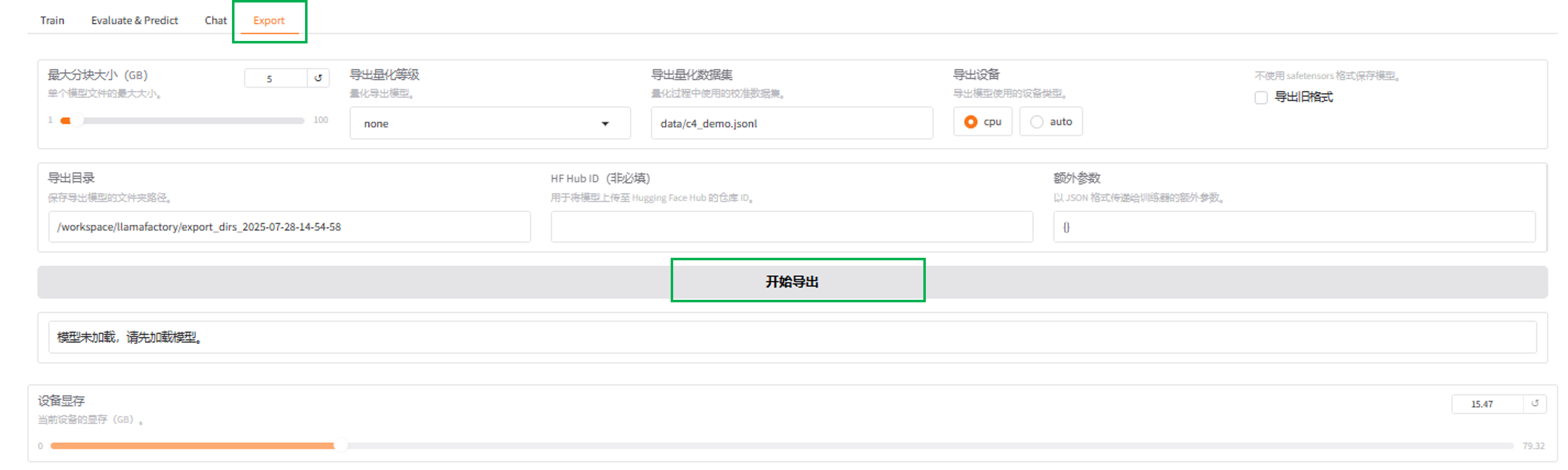
模型导出
在导出界面,您可以通过指定模型、适配器、分块大小、导出量化等级及校准数据集、 导出设备、 导出目录等参数后点击“导出”按钮,导出用户需要的模型。
VSCode和JupyterLab提供了悬浮操作框,支持一键切换编辑器、关机、重置资产、对外服务、最小化等功能。点击 图标可展开具体功能,如图中高亮(1)所示;点击
图标可展开具体功能,如图中高亮(1)所示;点击 图标则可收起悬浮操作框,如图中高亮(2)所示。
图标则可收起悬浮操作框,如图中高亮(2)所示。

悬浮框由上至下,从左至右的功能详解如下表所示。
| 序号 | 功能名称 | 详细说明 |
|---|---|---|
| ① | 实例控制 | 关机用于完全停止实例以停止计费,定时关机可预设时间以节约成本,重启则用于使系统更新或配置生效。 |
| ② | 开发环境切换 | 点击该按钮可在VSCode与JupyterLab两种环境之间快速切换,满足不同编程与调试需求。 |
| ③ | SSH远程连接 | 点击“SSH使用说明”可查看详细指引,您在此处可获取SSH远程连接的登录指令及登录密码。 |
| ④ | Secret Key | 点击“下载”链接获取密钥文件,您可参考“使用说明”完成SSH免密登录的配置。 |
| ⑤ | 资源使用情况 | - 实时显示当前实例所使用的计算资源类型(如 CPU/GPU)及使用数量,便于监控运行状态。 - 显示实例存储空间的已用与剩余容量,帮助用户管理文件和数据存储。 |
| ⑥ | 对外服务 | 平台为该服务分配的唯一访问地址,可通过此链接在浏览器中直接访问您部署的服务,端口号默认为6666。 |
对外服务支持用户从外部访问实例空间内的自定义服务。下面以外部服务访问Open-webui为例,在VS Code页面中的展示该功能操作步骤。(JupyterLab中的操作步骤与在VSCode中一致。)
-
通过VSCode启动实例后,点击页面左上角“Terminal”新建终端。
-
创建一个新的conda环境。(新环境名称为:open-webui,Python版本为:3.11)
conda create -n open-webui python=3.11 -y -
激活环境。
conda activate open-webui -
安装open-webui。
pip install open-webui itsdangerous -i https://pypi.tuna.tsinghua.edu.cn/simple/ -
启动open-webui。启动速度较慢,请耐心等待。
open-webui serve --host 0.0.0.0 --port 6666 -
启动成功后,点击悬浮操作框的“对外服务按钮”,复制地址。新开一个浏览器网页,将地址复制到地址框,实现外部访问open-webui。 可注册用户名和密码后登录。
 提示
提示环境中还未下载模型,无法进行模型对话。
-
(可选)使用open-webui进行模型对话。
-
下载Ollama。 回到最初的终端,按“ctrl+c”退出步骤5的命令。输入以下命令,下载Ollama。
curl -fsSL https://ollama.com/install.sh | sh -
启动Ollama服务。
ollama serve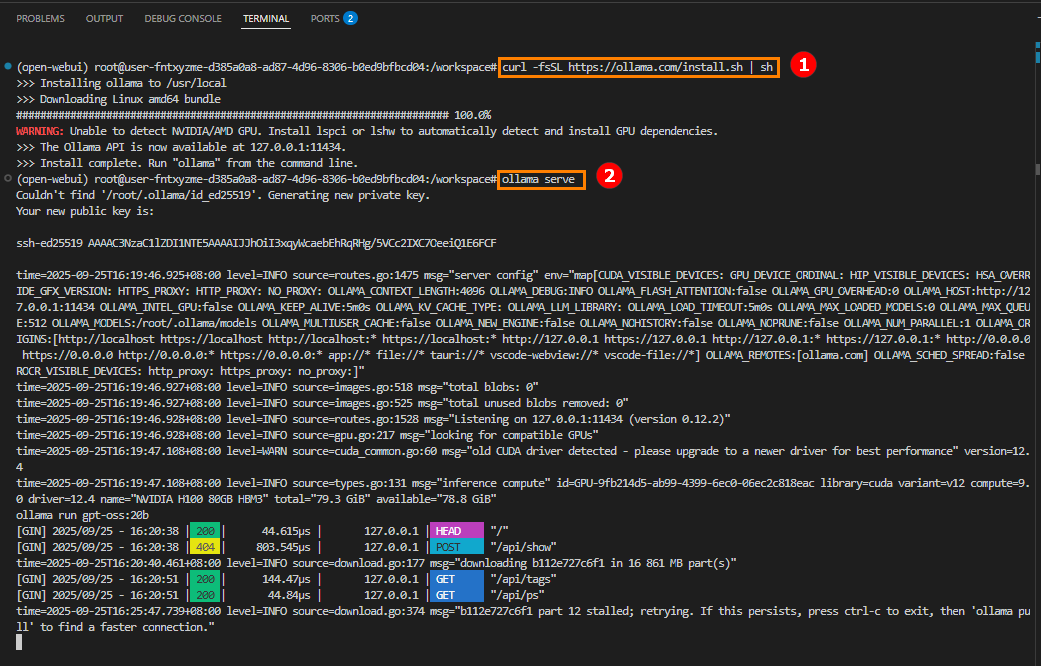
-
新建一个终端,进入open-webui环境,启动模型(以gpt-oss-20b为例)。
conda activate open-webuiollama run gpt-oss:20b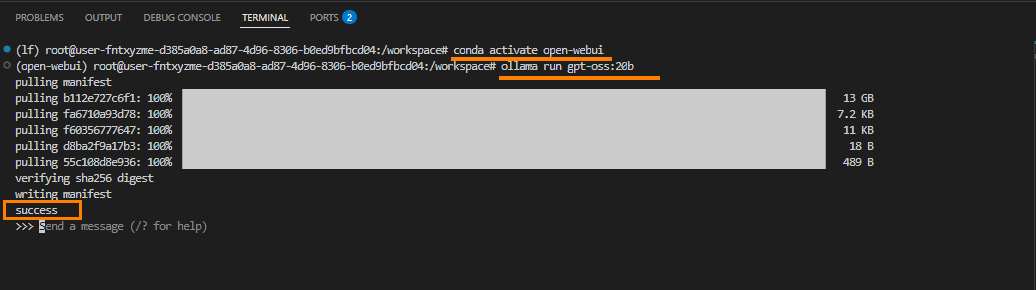
-
再新建一个终端,进入open-webui环境,启动open-webUI。
conda activate open-webuiopen-webui serve --host 0.0.0.0 --port 6666 -
启动成功后,点击悬浮操作框的“对外服务按钮”,复制地址。新开一个浏览器网页,将地址复制到地址框,实现外部访问open-webui。使用步骤6中注册的用户名和密码登录账户。在页面左上角选择模型:gpt-oss-20b,开始对话。
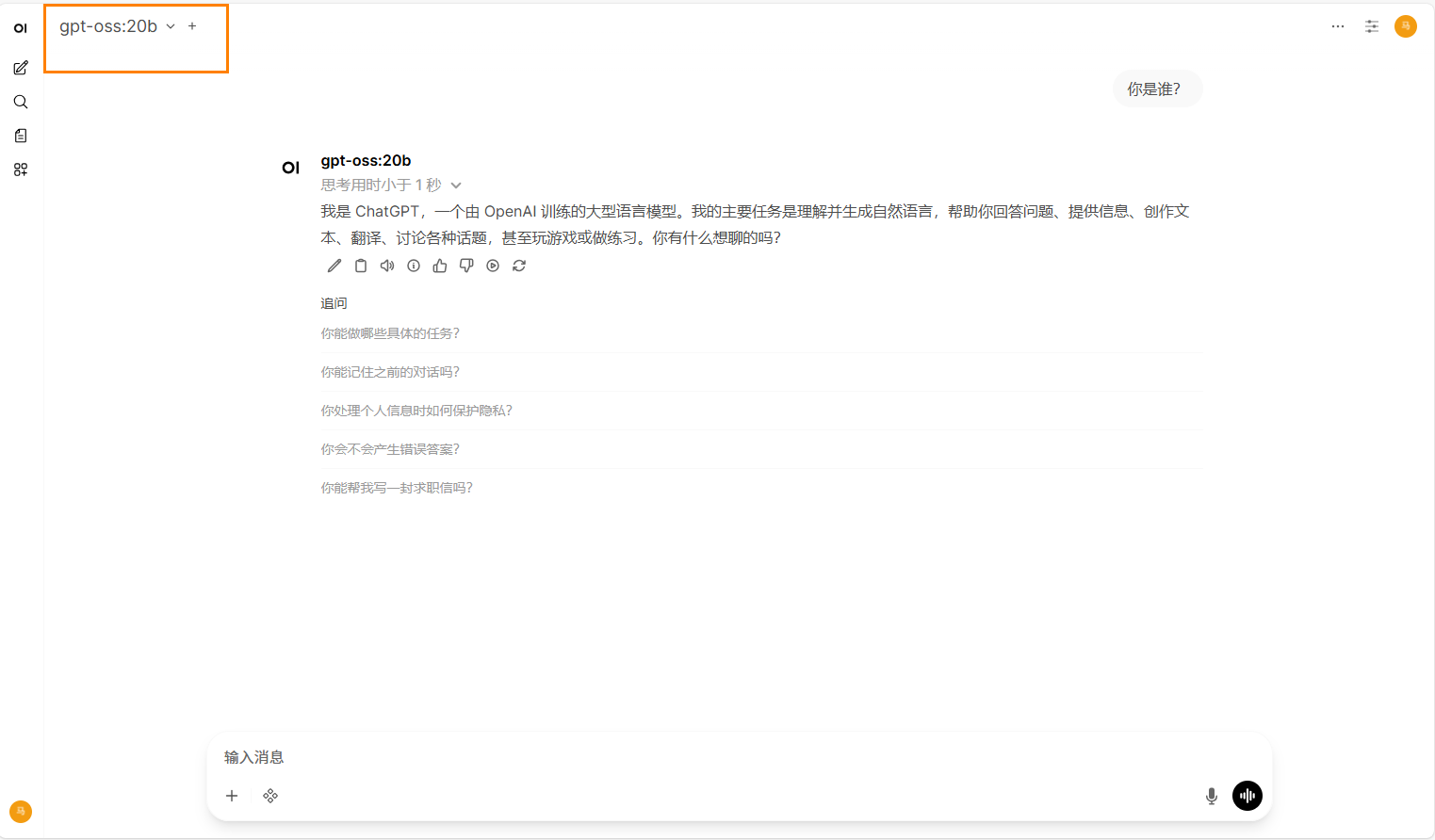
-
发布对外服务
以下示例以启动外部服务访问Open-webui为例,讲解在VScode中的操作步骤。
-
点击页面左上角 “Terminal” 新建终端,创建一个新的conda环境(新环境名称为:open-webui,python版本为:3.11);激活环境;安装open-webui;启动open-webui(启动速度较慢,请耐心等待)。
conda create -n open-webui python=3.11 -y
conda activate open-webui
pip install open-webui itsdangerous -i https://pypi.tuna.tsinghua.edu.cn/simple/
open-webui serve --host 0.0.0.0 --port 6666 -
启动成功后,点击悬浮操作框的“对外服务按钮”,复制地址。新开一个浏览器网页,将地址复制到地址框,实现外部访问open-webui。 可注册用户名和密码后登录。
提示环境中还未下载模型,无法进行模型对话。若想使用open-webui进行模型对话,请参考:实例管理->悬浮操作框->步骤7。
管理实例
- 登录账号后点击悬浮菜单栏的 “运行中实例” 按钮,找到对应的实例。
- 可快速管理实例资源,操作详情如下所示。
-
点击运行中实例的“关闭”实例按钮,例如下图所示,即可关闭正在运行的实例。
-
点击运行中实例的“重置资源”按钮,例如下图所示,即可进入资源重置页面。
-
点击运行中实例的“定时关机”按钮,例如下图所示,即可进入定时关机配置页面。
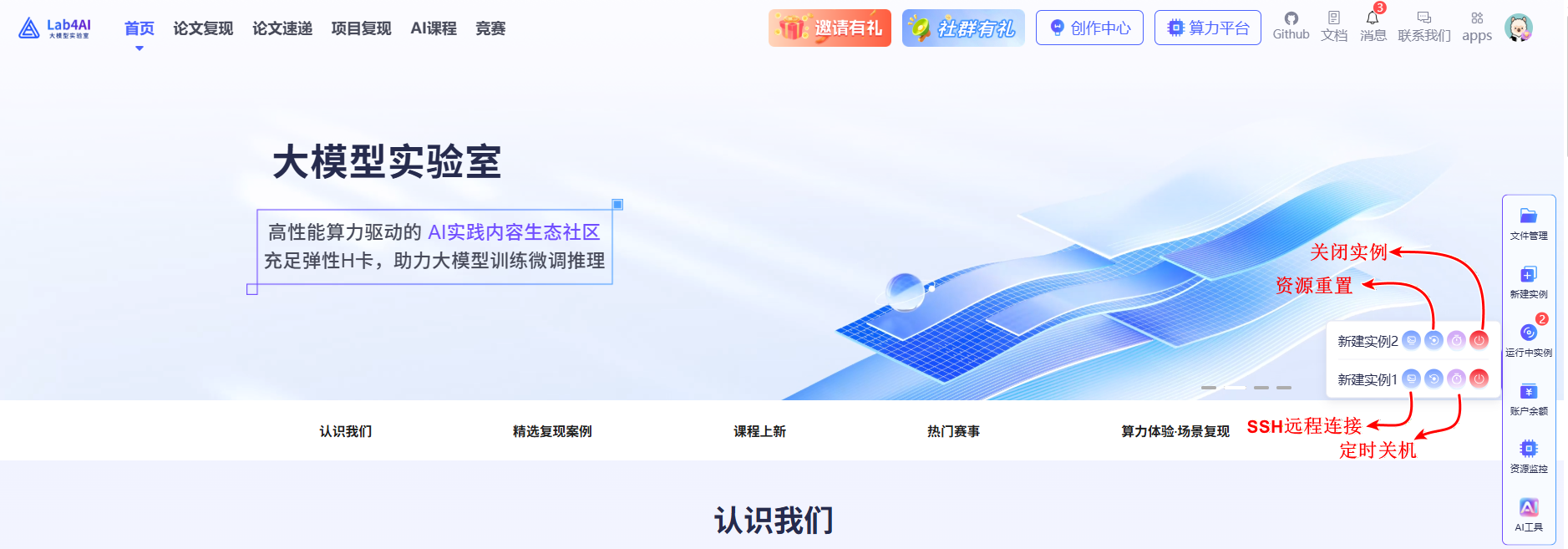
-
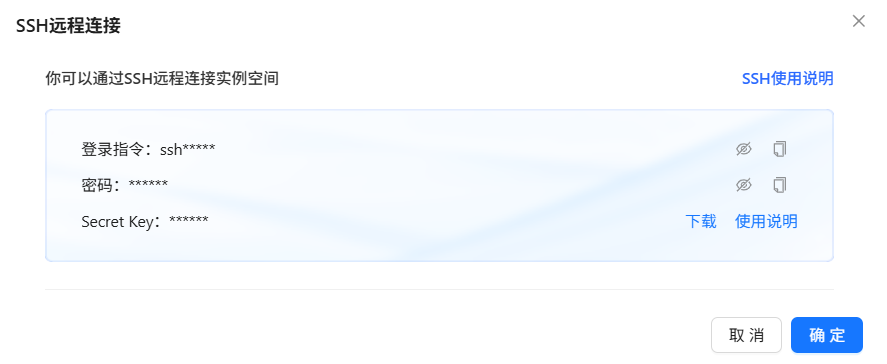
点击运行中实例的“SSH远程连接”按钮,即可进入SSH连接信息获取页面,例如下图所示,单击“SSH使用说明”链接可查看详细使用说明,您也可以下载免密配置文件,配置SSH免密登录。
-
点击运行中实例的 “SSH远程连接” 按钮,即可进入 SSH连接信息获取页面。在该页面中,您可以:
- 查看连接指引:单击 “SSH使用说明” 链接,获取详细的连接步骤、命令示例及常见问题解答,帮助您快速建立安全可靠的远程连接;
- 一键下载免密配置文件:系统将自动生成包含私钥和SSH配置的压缩包,您只需将其解压并导入本地SSH客户端,即可实现免密码登录,大幅提升运维效率与安全性。 通过以上功能,您可以更便捷、高效地管理云上实例,享受安全、流畅的远程操作体验。